Amazon Prime Video Selenium Scraper
Build a Selenium and BeautifulSoup Web Scraper that parses and generates a database of movie titles, ratings and synopses from the Amazon Prime Video homepage.
Get Started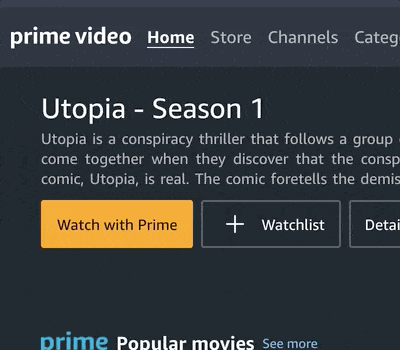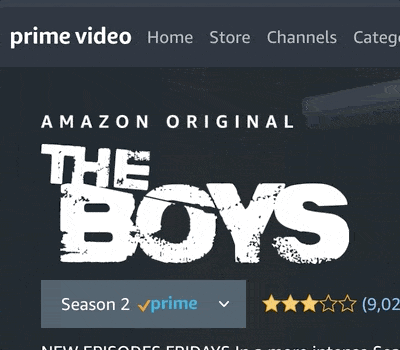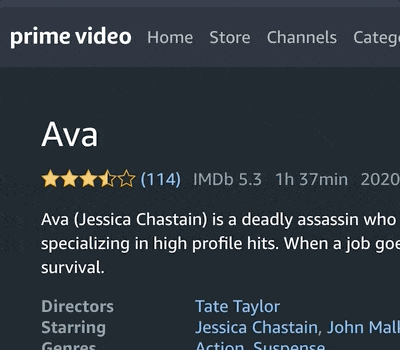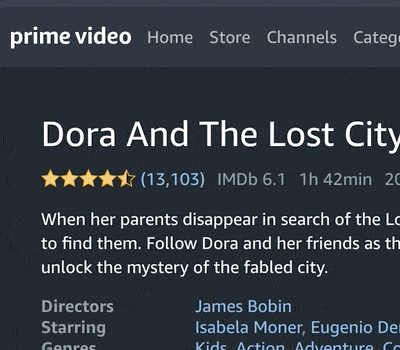
TECHNOLOGIES
WATCH TIME
31 minutes
LEVEL
Overview
Welcome to a beginner-friendly Python Project on Selenium and Web Scraping. We’ll build our own automation tool that scrapes the homepage of Amazon Prime Video for a list of movie and TV show titles, and then iterate through each link scraping key elements such as titles and ratings with BeautifulSoup. We’ll create our own database of content on the platform and then as a final example, visualize a word cloud with our dataset.
Project Tasks

Welcome to the project!
2 min

WordCloud Visualization of our Dataset
In this final task, I'll be teaching how to visualize the information we've gathered.
8 min

Setting up Selenium and our Chromedriver
In this video we'll be bootstrapping our Python project to prepare for the rest of the project.
6 min

Scraping and Automating Data Collection
Now that we have determined what we want from the HTML, we'll be telling BeautifulSoup how to pull the information and automating the process with Selenium.
10 min

Parsing our CSS Classes on Amazon Prime Video
In this video we'll be analyzing Amazon Prime's HTML source code and extracting all the key details.
7 min